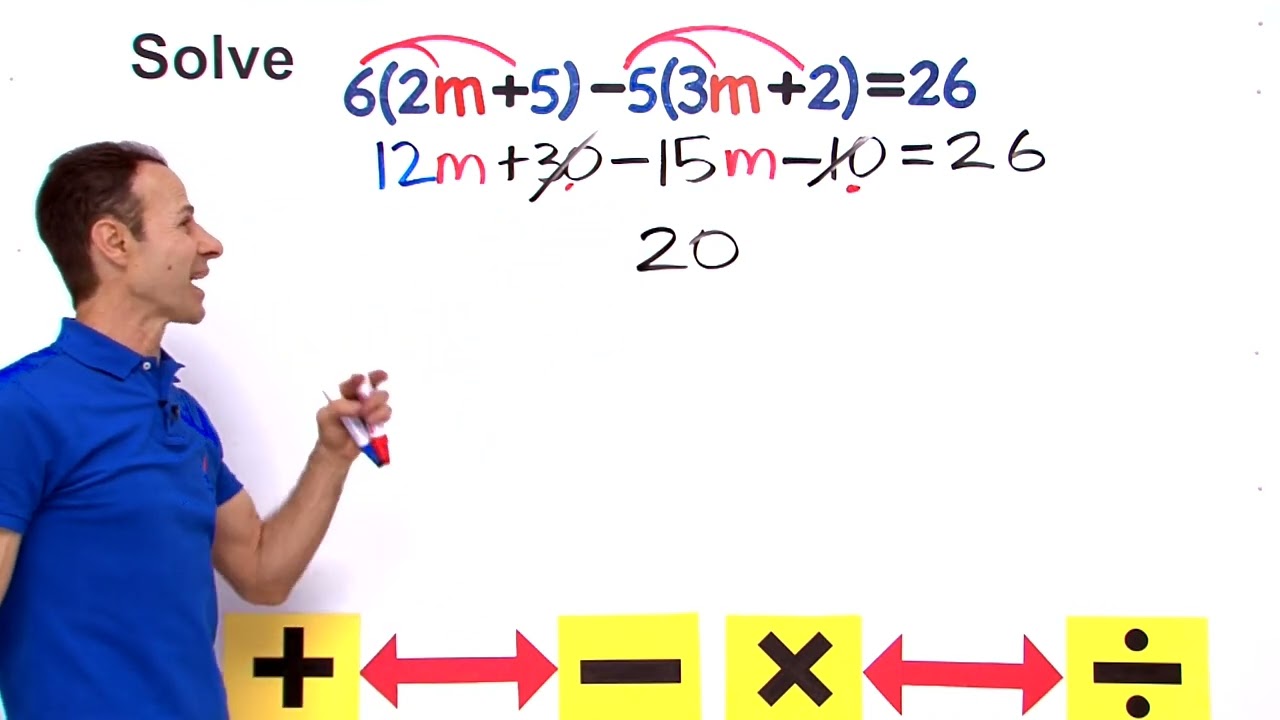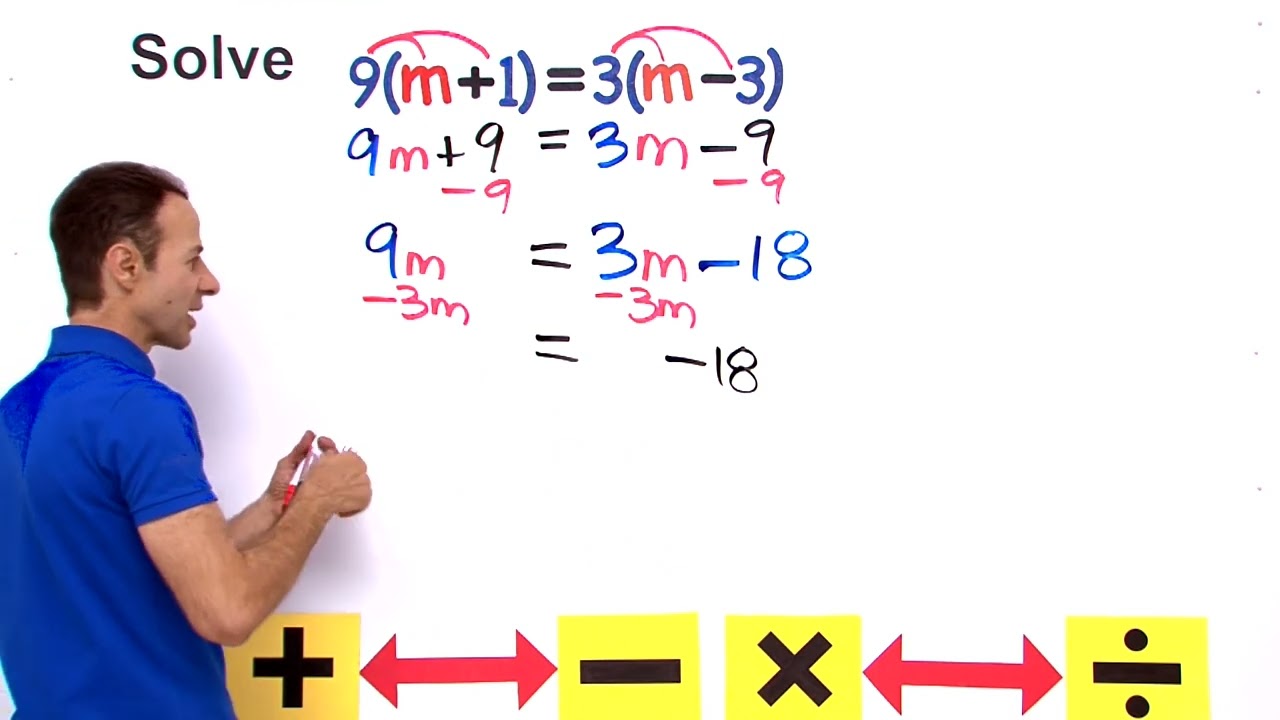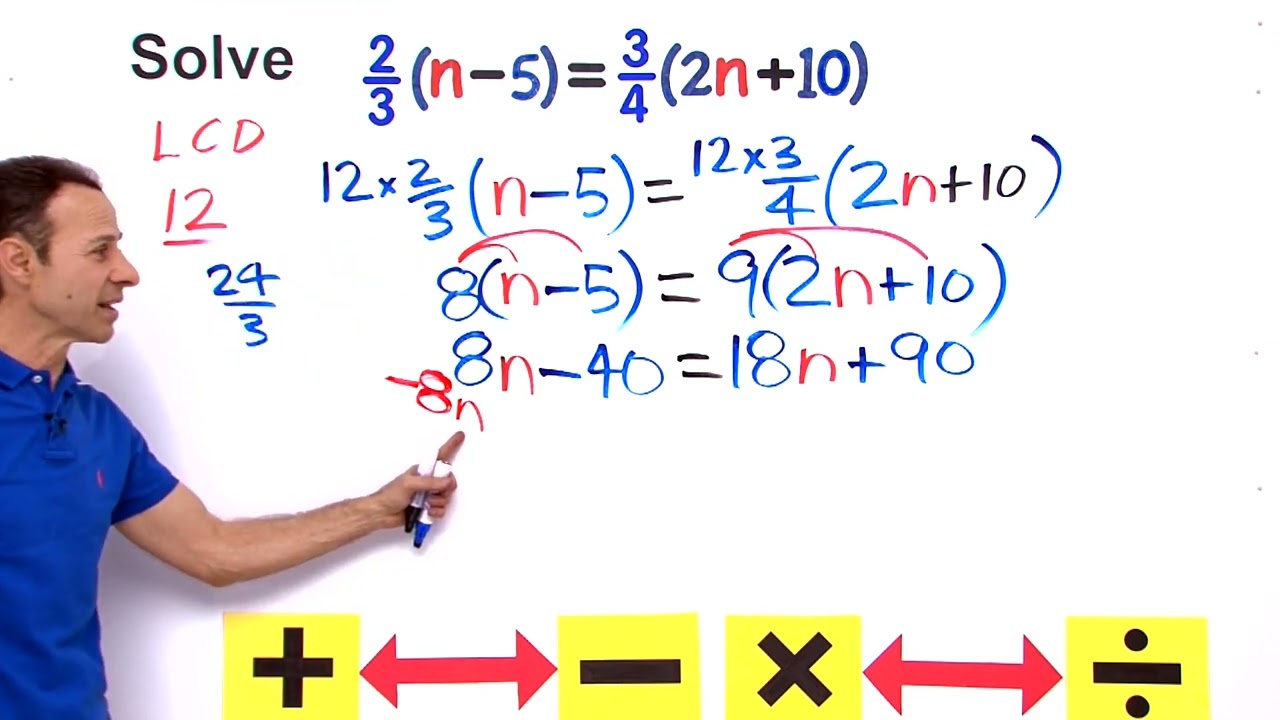Topics
My Insights
Login
Get Started
Menu
Home
Topics
My Insights
About
Contact
Login
Get Started
Topics
>
Algebra 1
>
Equations
>
Solve Equations with Variables on Both Sides using the Distributive Property
Solve Equations with Variables on Both Sides using the Distributive Property
Try
VividMath Premium
to unlock full access
Start Free Trial
Solve Equations with Variables on Both Sides using the Distributive Property
Video Quiz 1
Video Quiz 2
Video Quiz 3
Video Quiz 4
Solve Equations with Variables on Both Sides using the Distributive Property #1
Solve Equations with Variables on Both Sides using the Distributive Property #2
Solve Equations with Variables on Both Sides using the Distributive Property #3
Solve Equations with Variables on Both Sides using the Distributive Property #4
Solve Equations with Variables on Both Sides using the Distributive Property #5
Solve Equations with Variables on Both Sides using the Distributive Property #6
Solve Equations with Variables on Both Sides using the Distributive Property #7
Solve Equations with Variables on Both Sides using the Distributive Property #8
Solve Equations with Variables on Both Sides using the Distributive Property #9